3DCaricShop: A Dataset and A Baseline Method for Single-view 3D Caricature Face Reconstruction
Yuda Qiu1,2 Xiaojie Xu2 Lingteng Qiu1,2 Yan Pan1,2 Yushuang Wu1,2 Weikai Chen3 Xiaoguang Han#1,2*
*Corresponding email: hanxiaoguang@cuhk.edu.cn
1The Chinese University of Hong Kong, Shenzhen 2Shenzhen Research Institute of Big Data 3Tencent Game AI Research Center
CVPR 2021

Figure 1: With 3DCaricShop, the face geometry from a single caricature image can be inferred more accurately.
Introduction
Caricature is an artistic representation that deliberately exaggerates the distinctive features of a human face to convey humor or sarcasm. However, reconstructing a 3D caricature from a 2D caricature image remains a challenging task, mostly due to the lack of data. We propose to fill this gap by introducing 3DCaricShop, the first largescale 3D caricature dataset that contains 2000 high-quality diversified 3D caricatures manually crafted by professional artists. 3DCaricShop also provides rich annotations including a paired 2D caricature image, camera parameters and 3D facial landmarks.
To demonstrate the advantage of 3DCaricShop, we present a novel baseline approach for single-view 3D caricature reconstruction. To ensure a faithful reconstruction with plausible face deformations, we propose to connect the good ends of the detailrich implicit functions and the parametric mesh representations. In particular, we first register a template mesh to the output of the implicit generator and iteratively project the registration result onto a pre-trained PCA space to resolve artifacts and self-intersections. To deal with the large deformation during non-rigid registration, we propose a novel view-collaborative graph convolution network (VCGCN) to extract key points from the implicit mesh for accurate alignment. Our method is able to generate high-fidelity 3D caricature in a pre-defined mesh topology that is animation-ready. Extensive experiments have been conducted on 3DCaricShop to verify the significance of the database and the effectiveness of the proposed method.
Publication
Paper - ArXiv - pdf (abs) | GitHubIf you find our work useful, please consider citing it:
@inproceedings{qiu20213dcaricshop,
title={3DCaricShop: A Dataset and A Baseline Method for Single-view 3D Caricature Face Reconstruction},
author={Qiu, Yuda and Xu, Xiaojie and Qiu, Lingteng and Pan, Yan and Wu, Yushuang and Chen, Weikai and Han, Xiaoguang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10236--10245},
year={2021}
}
Dataset
We contribute to 3DCaricShop dataset, a large collection to caricature face images and the corresponding 3D models manully crafted. The dataset proposed has two appealing features:- Firstly, 3DCaricShop contains 2000 models reconstructed from diverse 2D caricature images, which covers 247 celebrities. To the best of our knowledge, 3DCaricShop is the first largescale 3D caricature dataset manually crafted by professional artists.
- Secondly, 3DCaricShop contains rich annotations including 3D key points and the corresponded transform matrix for images. In addition, the 3D meshes in 3DCaricShop are topologically uniform.
Data Examples

Figure 2:Examples of 3DCaricShop.
Dataset Statistics
We quantitatively analyze our dataset by comparing the shape variations with two normal face datasets (FaceWarehouse and FaceScape), as well as one synthetic caricature dataset, FaceWarehouse with deformation (Aug. FaceWarehouse). We measure the shape variation using global and part variance. In particular, the variance is computed between the models and their corresponding mean shape of each dataset in terms of per-vertex displacement. The results are presented below. The shape diversity of our dataset is richer than the normal ones. For most of the face regions, 3DCaricShop has larger shape variance than Aug. FaceWarehouse.
| Dataset | Global | Eye | Nose | Mouth | Ear | Cheek | Face |
|---|---|---|---|---|---|---|---|
| FaceWarehouse | 3.41 | 0.71 | 0.61 | 2.60 | 4.41 | 1.43 | 3.40 |
| FaceScape | 2.17 | 0.36 | 0.15 | 2.63 | 5.57 | 1.24 | 2.27 |
| Aug. FaceWarehouse | 5.06 | 1.98 | 6.29 | 2.07 | 9.38 | 5.26 | 5.10 |
| 3DCaricShop | 8.26 | 4.68 | 3.04 | 10.90 | 9.02 | 8.27 | 6.95 |
Table 1: The shape variation for 3d face datasets.
Experiment Results
Benchmarking on Single Image Reconstruction
Figure 3 shows qualitative results of our method compared with state-of-the-art methods, including (a) 3DMM from normal face (3DMM-Human) , (b)3DMM from 3DCaricShop (3DMM-Caric) , (c) DF2Net , (d) AliveCaricature-DL and (e) PiFu, on 3DCaricShop. By incorporating deep models with parametric space constraint, our method (g) can reconstruct highly exaggerated geometry without distinct artifacts.
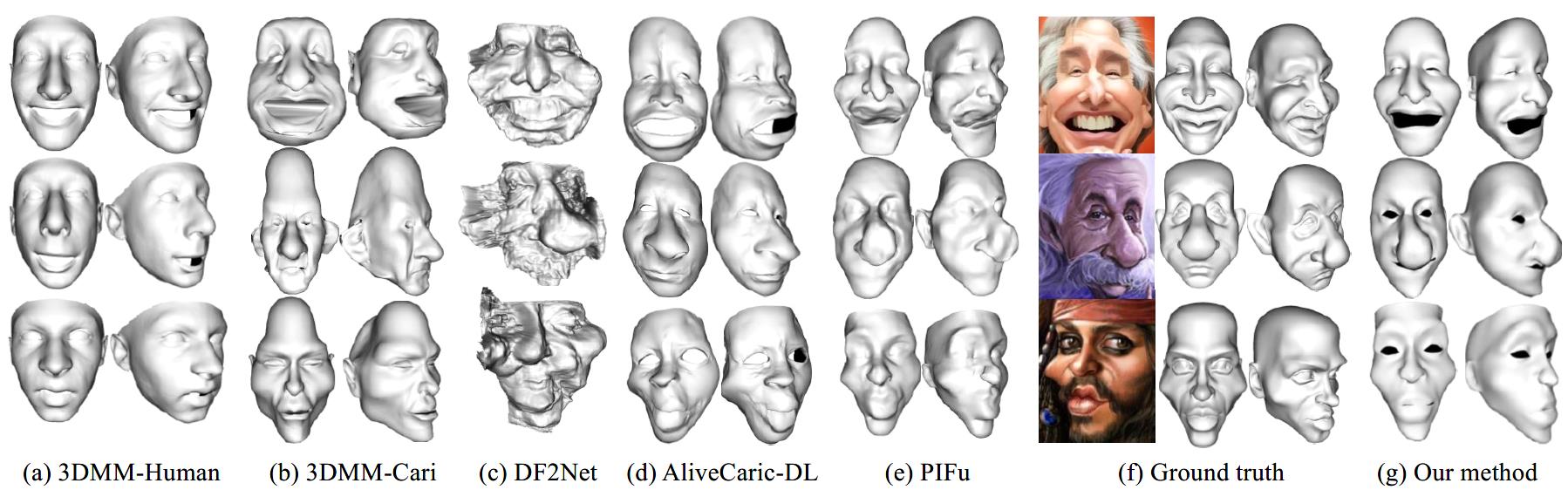
Figure 3:Experiment results against other methods.

Figure 4:Results gallery.
Rigging Results
In the Figure 5, we compare the rigging results with AliveCaricature-DL. Both results are animated using the same skeleton and skinning weights for fair comparison.
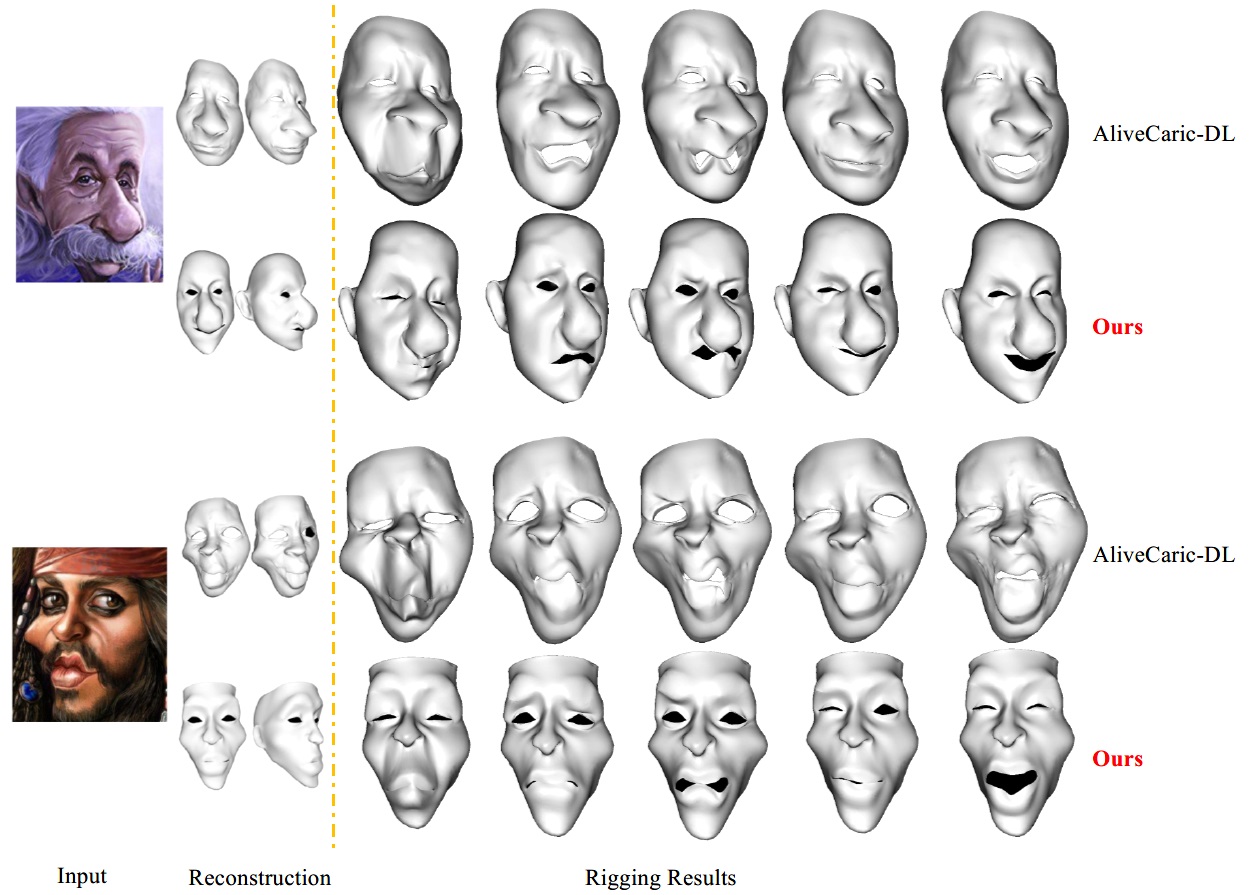
Figure 5:Experiment results on rigging.